
Multimodal Assistant
Explore the power of multimodal AI. This example shows how to handle images, PDFs, and audio files alongside text prompts using models like GPT-4o.
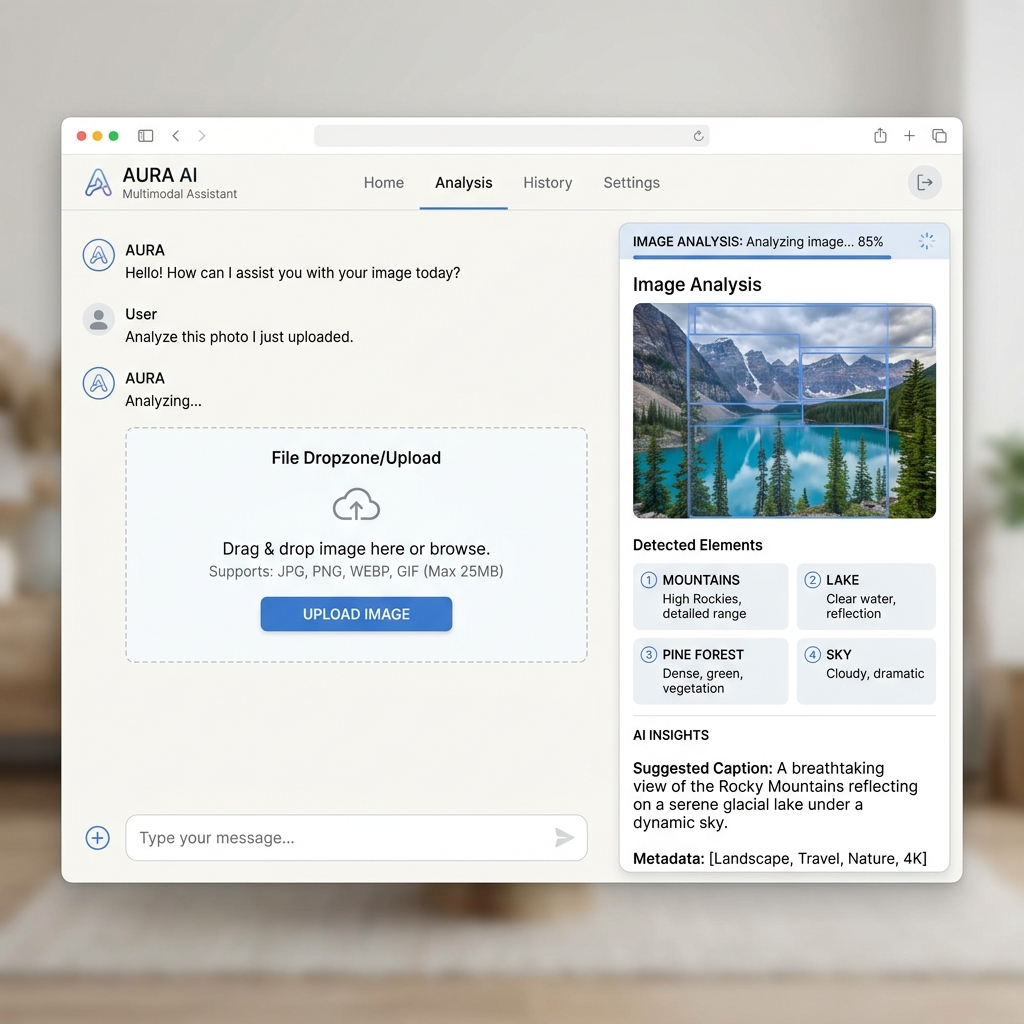
Core Capabilities
Every starter is pre-configured with industry best practices and deep AINative integrations. Clean, modular, and designed to scale from prototype to production.
Vision support for image analysis
Enterprise-ready implementation with full type safety and observability. Optimized for high-throughput streaming and minimal latency.
Document processing (PDF, TXT)
Optimized for Edge runtimes and serverless environments.
Audio transcription and analysis
Secure by default with built-in validation and CSRF protection.
Unified drag-and-drop input
Deep integration with the AINative Reconciler state system for buttery smooth UI updates and zero-flicker streaming.
Technical Stack
Clean, modular, and designed to scale from prototype to production.
Frontend Layer
Reactive hooks and streaming primitives.
import { useMultimodal } from "@ainative/react";
export function MultiAssistant() {
const { uploadFile, submitPrompt } = useMultimodal();
return (
<div>
<Dropzone onDrop={files => files.map(uploadFile)} />
<Input onSend={submitPrompt} />
</div>
);
}Backend Adapter
Universal protocol handlers for any runtime.
import { MultimodalHandler } from "@ainative/server-node";
export const POST = MultimodalHandler({
provider: "openai",
model: "gpt-4o",
enableVision: true,
enableAudio: true
});